Pandoc and Python
I’ve talked before about using Pandoc to convert Markdown to LaTeX. I’ve been using it a lot this year, and it’s been great to write more in Markdown and code less in LaTeX. Pandoc does a really nice job converting Markdown and even characters like $, %, —, etc. into the correct LaTeX syntax (\$, \%, ---, etc.). It also leaves alone any chunks of LaTeX I intersperse in my Markdown files (e.g. equations) so that they’re still there in the final LaTeX output—married with the LaTeX created from Markdown.
So that’s all the good. For me, the bad of Pandoc is that I don’t think the LaTeX code it generates is very nice to look at. It typesets just fine, but Pandoc inserts extra line breaks by default and does funny things with itemize and enumerate environments that make reading the LaTeX code later difficult—especially annoying when I need to go back into the LaTeX to edit/add things in the future.
Fortunately I’ve been able to address these shortcomings by learning more about Pandoc’s options and bringing Python into the mix.
To illustrate, let’s start with some Markdown written in Ulysses, which I use a lot for writing on both macOS and iOS:

If I copy that Markdown to my clipboard and run a basic pandoc command in terminal like:
pbpaste | pandoc -f markdown -t latex | pbcopy
It will create the following LaTeX (shown in Sublime Text 3):
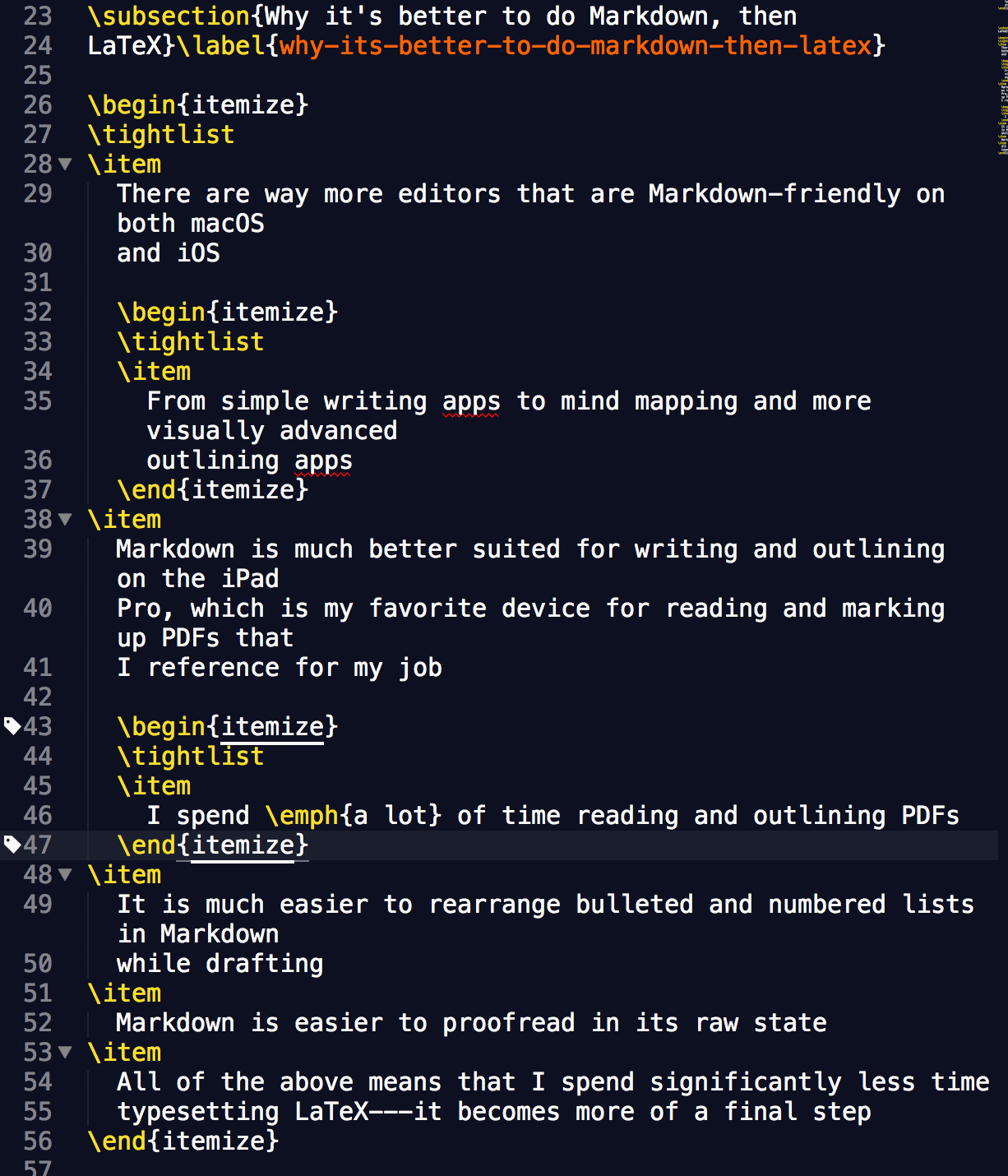
If I never need to look at the LaTeX code again, this isn’t so bad. It will typeset just fine. But it’s very messy. Namely:
- Pandoc uses a
\tightlistcommand to reduce line spacing inside itemize environments. This is unnecessary for me because I have preset styles for bulleted lists in itemize environments. - Pandoc prefers to keep each
\itemon its own line. This is very inefficient space-wise because you’ll always have at least two lines for each item in a bulleted list. Visually it just looks bad to me because\itemrepresents a bullet, which will precede the text on each line in the actual PDF (like all bullet points do). - By default, Pandoc truncates lines to 60-something characters—essentially assuming the text will be viewed in a text editor that doesn’t wrap lines. As you can see in the screenshot above, I have Sublime Text 3 set to wrap lines for LaTeX because it usually makes LaTeX easier to read. This is just one aspect of LaTeX that makes it more prose-like than code-like. Paragraphs and long lines should not have arbitrary line breaks.
Fortunately, Pandoc’s developers later added an option to preserve wrapping, which solves problem 3 above:
pbpaste | pandoc -f markdown -t latex --wrap=preserve | pbcopy
To fix problems 1 and 2 above (as well as others), I turned to Python, a move that was very wise in hindsight because it lead me to finally develop a reliable process for executing shell commands within Python—something I can see myself using a lot in the future for all kinds of things.
This is my current Python script:
import subprocess
from subprocess import Popen, PIPE, STDOUT
import sys
import re
# Function to get system clipboard contents
def getClipboardData():
p = subprocess.Popen(['pbpaste'], stdout=subprocess.PIPE)
retcode = p.wait()
data = p.stdout.read()
return data
# Function to put data on system clipboard
def setClipboardData(data):
p = subprocess.Popen(['pbcopy'], stdin=subprocess.PIPE)
p.stdin.write(data)
p.stdin.close()
retcode = p.wait()
# Get Markdown copied to clipboard
input_text = getClipboardData()
# Popen pandoc shell command
p = Popen(['pandoc', '-f', 'markdown', '-t', 'latex', '--wrap=preserve'], stdout=PIPE, stdin=PIPE, stderr=STDOUT)
# Pass Markdown text to pandoc through stdin and get raw LaTeX from pandoc
latex = p.communicate(input=input_text)[0]
# Clean LaTeX:
latex = re.sub(r'\\tightlist\n', r'', latex) # remove \tightlist
latex = re.sub(r'\\item\n\s+', r'\t\\item ', latex) # join \item with its text on a single line; also put tabs in front of \item
latex = re.sub(r'\\label.*', r'', latex) # remove all LaTeX labels
setClipboardData(latex)
getClipboardData() and setClipboardData(data) are functions that I stole from Macdrifter. They are really handy for working with the clipboard in macOS. Since I work with Markdown in a lot of different ways, copying it to my clipboard has been the best all purpose way of getting it into a script like this.
The biggest innovation in this script, for me, is Popen and communicate from the subprocess module. This is really powerful stuff because it basically lets me execute shell commands and work with stdin and stdout just like I would if I was running ad hoc Terminal commands.
In my script, communicate passes the Markdown text via stdin to the pandoc shell command, then sends the pandoc output through stdout back to Python as a string. This was a huge milestone because once I had the raw LaTeX in a text string within Python, it made it possible to use Python to clean the LaTeX any way I liked.
The final part of the script runs several regular expression substitutions to clean the output more. Honestly, these could have been done just as easily with the basic replace method, but I have a commitment to myself to use regular expressions as often as possible to get better at them.
Running the script results in LaTeX that I think is much easier to read and takes up a lot fewer lines:
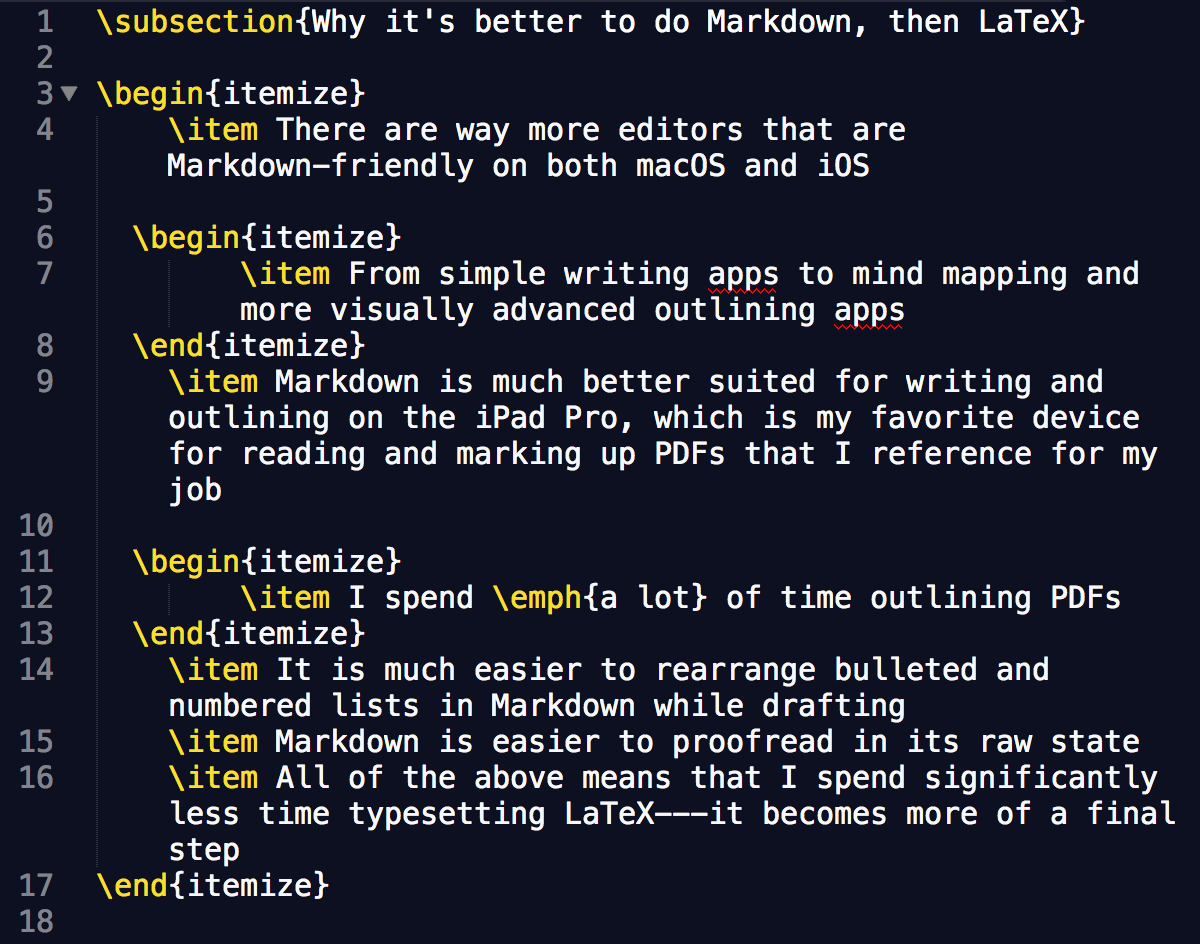
I’m sure there are a thousand better ways of accomplishing what this script does for me, but I’m really happy that I can continue writing more LaTeX-bound text in Markdown and know that the final LaTeX will be even easier to work with in the future. It’s also opened the door for a lot more Python automation, which on some level, is probably the entire point of investing time in automation.