- Don’t check email in the morning
- Only check Twitter once per day
- Don’t eat dessert Monday through Friday
- Look at the stock market only once per week
- I learned that I can change the default folder for screenshots from the Desktop folder to Downloads (or any folder). My Downloads folder is an all purpose inbox that gets regularly cleaned by Hazel. It’s also easier to drag temporary files from the fan view of my Downloads folder in my dock than it is to show the Desktop.
- I started using “All my files” in the Finder to quickly locate recently modified files for uploading in web forms, or to locate a file I accidentally saved in the wrong place on my Mac. The “All my files” search folder has been there forever. For some reason, I started taking advantage of it just a few months ago. It’s also a simple reminder of just how powerful the Mac filesystem itself is as a content management system.
- I (surprisingly) embraced Siri on the Mac: “Show me keynote files I had open yesterday” and similar commands work flawlessly. Speaking really specific commands like that is much more efficient than doing custom Spotlight searches.
- I moved to PDF Expert for almost all PDF editing and annotation tasks for two main reasons: 1) PDF Expert has gotten really good at the things I do to/with PDFs on a regular basis and 2) Preview.app in macOS Sierra can no longer be trusted not to break PDFs.
- Fire in the Mind by George Johnson was the best book I read.
- The Science of Mindfulness, an audio course by Dr. Ronald Siegel, was the best thing I listened to.
- Pandoc uses a
\tightlistcommand to reduce line spacing inside itemize environments. This is unnecessary for me because I have preset styles for bulleted lists in itemize environments. - Pandoc prefers to keep each
\itemon its own line. This is very inefficient space-wise because you’ll always have at least two lines for each item in a bulleted list. Visually it just looks bad to me because\itemrepresents a bullet, which will precede the text on each line in the actual PDF (like all bullet points do). - By default, Pandoc truncates lines to 60-something characters—essentially assuming the text will be viewed in a text editor that doesn’t wrap lines. As you can see in the screenshot above, I have Sublime Text 3 set to wrap lines for LaTeX because it usually makes LaTeX easier to read. This is just one aspect of LaTeX that makes it more prose-like than code-like. Paragraphs and long lines should not have arbitrary line breaks.
LaTeX comes to Pages
As you may have heard, Pages now supports LaTeX equations in both iOS and macOS. Even though it’s not nearly as robust as writing and typesetting LaTeX using MacTeX, it’s extremely well implemented and will be a huge convenience, especially for one-off files and shorter documents.
I like how the Equation editor in Pages provides a live preview of the equation as you type it:

As an added bonus, even though Keynote does not have the same direct LaTeX support as Pages, I found that you can copy the equation in Pages as an image and simply paste it into Keynote. The image appears to be a vector graphic because it scales perfectly without any resolution loss.

In a nutshell, this means you can also quickly add equations to Keynote via Pages on the fly.
LiquidText 3.0 redefines what's possible with a PDF and an iPad once again
MacStories has a nice review of the latest update to LiquidText. At last, it supports the Apple Pencil.
Part of what makes this version of LiquidText so amazing to use is that your finger and the Pencil can do different things. It’s like having two tools in your hand.
Finger selections can make excerpts even while the Pencil is in drawing or highlighting mode. The Pencil can draw anywhere—not just on the PDF like most PDF editors, but even in the LiquidText workspace, right alongside your excerpts and comments.
You can even drawn a circle or box around anything in the PDF, and it extracts it as an image to the workspace. The image can be copied to your clipboard and even pasted into other apps. This is the first time I’ve ever been able to capture a portion of a PDF as an image without having to screenshot the whole screen and crop in Photos. This opens a lot of possibilities—like being able to capture a graphic and paste it into an app like Notability, to collect it with other visual notes.
The makers of LiquidText are really redefining what you can do with an iPad. Bigger picture, the iPad Pro + Apple Pencil + software like LiquidText, DEVONthink, PDF Expert, and Notability make for an incredible PDF system—one that is way more powerful than a traditional desktop computer.
Next fun
If a project, task, or reminder is stalled, overly deferred, or procrastinated, the correct next action is always: Decide how to make this fun.
The cost of monetization
David Heinemeier Hansson going off on monetization schemes:
Consumption of monetized apps should always be pondered with skepticism. The whole lot of them fall into what we should label “a family of products with known mental carcinogens; further study recommended”.
Consume or be consumed.
Regular expressions and Sublime Text
Regular expressions seem very difficult to learn at first, but once you get the hang of them, they are powerful tools. I’m using them more and more in Python scripts and also find/replace workflows in Sublime Text.
Since I have several regular expressions that I use over and over (and over) again, I decided to store them in TextExpander for quick reference. I prefix each snippet with rx, which lets me use the TextExpander global shortcut to bring up a TextExpander search box anywhere in macOS so I can just grab the one I need.

Using regular expressions to find text in Sublime Text is easy, but remember to press the .* button on the far left of the find/replace form first.

Regular expressions are even more powerful when you learn the “replace” syntax in Sublime Text. In the screenshot above, the regular expression ^.*\{frame\} is designed to find lines containing the LaTeX Beamer frame environment and match all text from the beginning of the line through the closing } to the right of frame.
By enclosing this search term in parentheses, I’m telling Sublime Text that I want to use it as a variable in my replace term. The variable is called $1. (You can separate multiple search terms with commas, to get $1, $2, etc.)
Therefore my replace term % $1 will effectively insert the % (LaTeX comment symbol) at the beginning of each matched line. This comments out all lines containing the frame environment so that LaTeX will ignore them—something that’s very useful in one of my LaTeX workflows.
But anyway, if you use Sublime Text a lot and want to take your find/replace routine to the next level, regular expressions are your friend.
RegExRX is a really handy Mac app for building and testing regular expressions.
Use universal clipboard to alleviate iCloud password pain
Amid the storm of negative narratives on the state of Apple—and more generally how horrible life is today in the First World with all the worry over our expensive computers—it’s easy to lose sight of the fact that some things really are more awesome today than they used to be. And there is still much delight to be found in the details.
One dash of unicorn tears introduced by iOS 10, and then later brought to macOS in Sierra, is universal clipboard. When I first heard Apple announce it, I was skeptical, but I really wanted to believe it would work. I imagined being able to copy text on my iPhone and paste it on my Mac (and vice versa). As amazing as that idea sounded last summer, actually seeing it work is even more amazing. I’ve yet to see it not work.
Very recently I came across a use case for it that I never envisioned before: copying my iCloud password from one device to another. Before universal clipboard, if I had to enter an Apple ID or iCloud password in a prompt on, say, an iPad screen, I had to close the prompt, find 1Password, copy the password, then return to the prompt.
Now, if I encounter a password prompt on an iPad, I just pull out my phone, copy it from 1Password there, and bang: It pastes right into the field on the iPad—even from the initial “splash” iCloud screen you get after an iOS update. Magic meets practicality.
I still think Apple could alleviate iCloud password pain by making Touch ID more available on general password prompts in the App Store and iTunes, but with universal clipboard, life is just a little less bad in the First World.
Simple PDF saved search tip
If you’ve been using a Mac for a while, you probably know about smart folders, which are essentially saved searches. I’ve known about them for a long time, but for some reason never used them much. I’ve started to realize this was a huge mistake.
Smart folders can be very specific and complicated, but even a simple one that looks for all PDFs across the file system is an incredible time saver. Being able to see recently modified PDFs from different applications in a common “folder” so that I can combine them and use them in different ways is way easier than doing PDF-specific searches or having a bunch of Finder windows open at once.

The core feature of the Mac that’s yet to be replicated by iOS is the file system. The ability to have files scattered across a file system that any installed app can access is a taken-for-granted aspect of computing that I hope we never lose. For now, we haven’t, and I plan to use the hell out of it.
To don't streaks
Being January, a lot of people have habit-forming on the brain. My favorite app for habit-forming is Streaks, which is designed to encourage you to complete tasks over consecutive days, X times per week, etc. It can even read health data from your iPhone and automatically check off health-related tasks.
I think most people approach habit-forming in terms of “things I want to do,” and that was generally me before 2016. But in 2016, I started taking a more inverted approach and embraced the “to-don’t.” I’m willing to bet for most people in modern times, you’ll find more low hanging fruit in to-don’t lists, which are simply lists of things you do not want to do.
Great examples of things to not do or just do less:
I have had a lot of success with the “only once per day” variety. It’s really amazing how easy the internet makes it to check in on useless information and how much attention that destroys. It only takes one or two well-designed to-don’ts to indirectly make way for a significantly more focused day.
Building long streaks of to-don’ts with an app like Streaks is surprisingly easy, and it’s really empowering to see that you only did something once per day for the last, say, 45 days, that you used to do 100 times a day.
Things I got better at in 2016: Part 2 -- Time and project management
Also see part 1 on technology things.
Honing time management skills is a lifelong process that starts at an early age. I don’t think it’s something that is perfectible. Instead, it’s something that someone can simply get better at with maturity and awareness. I feel like 2016 was my best “time management year” ever because of what I accomplished and the efficiency I felt in the day-to-day moments of my work.
Based on self observation, these are the aspects of time and project management that I think I improved on the most.
Time management
I dedicated mornings to deep reading and tasks that require the most mental energy. I’ve always known that I do my best work in mornings, but in 2016 I made my most concerted effort ever to guard mornings for specific kinds of work.
It’s a nuanced thing I guess, but the biggest change I made was that I stopped working on projects as linearly as I used to. Rather than use any time available to work on the “next task in line,” so to speak, I began carving projects up into more specific task categories using OmniFocus contexts.
I’ve never been a fan of contexts like “high energy” and “low energy,” but I’ve learned to associate specific stages of my typical projects with energy states, which are largely dependent on the time of day. In doing this, I made more progress over longer time periods because projects were less likely to stall on high energy tasks that I used to try to take on in afternoons. Once afternoon rolled around, if a high energy task was next in line, I learned to let it go until the next morning, and I looked for lower energy (e.g. administrative tasks) to tackle.
It’s kind of like learning to knock down a huge brick wall by chipping away at different spots until the whole thing collapses under its own weight, rather than tearing it down brute force brick-by-brick from right to left. At first it feels like you’re making less short-term progress when you take a more energy-based approach to work, but over longer periods, I believe you begin accomplishing not only a greater quantity of work, but a higher quality of work because at each stage, you give the work the appropriate amount of attention.
The other benefit I began to feel is that I started keeping my admin-oriented tasks to a manageable number. They stopped piling up because I was able to knock them out during times of day that my mind was useless to work on higher value work anyway.
I’ve begun to understand that I’m essentially a collection of “selves” that change subtly throughout the day, and I’ve learned to manage these “selves” as different workers—or like a great football coach who knows how to get each player to play to his full potential.
I also became much more aware of how important sleep is to getting more out of all these “workers.” The closer I can come to seven-ish hours of sleep a night—not just in a given night, but in consecutive nights consistently—the higher I perform at every stage of the day.
Project management
I finally bought OmniPlan in 2016, and within only a few days of using it, my biggest disappointment was that I hadn’t bought it sooner. I’m probably a very unusual user of OmniPlan because I’m not a “project manager” in the formal sense, and I’m not using it to manage projects with multiple people.
For me, it’s just very useful to have a time forecast for projects so that I can set realistic expectations for myself and my customers. Knowing when a project will likely end also lets me do more macro-level project planning to understand what I can realistically accomplish in the coming months or year so that I’m less likely to over-promised my time. Gantt charts are definitely not unique to OmniPlan, but I really like how the OmniGroup has implemented them in OmniPlan and how easy it is to work with them.
OmniPlan makes it very easy to create task dependencies and realistically budget for weekends, holidays, and other planned time off. There is nothing better than taking time off and knowing your work is still on schedule when you get back.
I’m using OmniPlan exclusively in iOS. It’s really great on my big iPad Pro, but it’s also surprisingly well implemented on the iPhone. I may buy the Mac version at some point, but the iOS version is satisfying all my needs for now.
For me, OmniPlan complements OmniFocus. I used OmniFocus more than ever in 2016. In 2015, I began a trend of creating more, smaller OmniFocus projects rather than fewer, larger projects. The longer-term, multi-week and multi-month projects I track in OmniPlan are usually organized within specific folders in OmniFocus. Very roughly speaking, each OmniFocus project is corresponds to one or two tasks in OmniPlan.
In OmniPlan, my goal is to forecast time, and so the tasks I create in OmniPlan need only be granular enough for that purpose. OmniFocus actions are much more granular, representing the steps I need to execute in the day-to-day and moment-to-moment to moment work of the project.
At first I was worried I was just duplicating administrative work in OmniPlan by doing what can feel like recreating tasks there. But the return on this additional time investment has been huge. OmniPlan essentially gives me an additional time-oriented perspective of my projects that I don’t have in OmniFocus (or any other task management tool). For longer projects, it’s also very motivating on a daily basis to see how staying on a preset schedule today translates to time savings weeks in the future. It also helps avoid the natural tendency to waste time until a fast approaching deadline forces urgency.
Bigger picture
For most knowledge work, “project management” reduces to simply time management. Good planning is about turning each day into an urgent, but achievable deadline.
Things I got better at in 2016: Part 1 – Technology
This is a miscellaneous list of things I feel like I got better at in 2016 and hope to build on even more next year. Also see part 2 on time and project management.
Regulator expressions
Maybe just through sheer resolve, I finally got better at writing regulator expressions in 2016. If you work with text files in any capacity, learning regular expressions is well worth your time. They are so much more efficient than writing loops in scripts to clean up text files, and they really take ad hoc “find/replace” fixes to the next level in text editors like Sublime Text.
There are infinite practical use cases for regular expressions if you can punch through their opaque syntax. For example, I can search for all hyphens that occur at the beginning of a line if I want to manipulate the indentation of a Markdown list.
Python
I continued to increase my time investment in Python, which has become my all-purpose programming language for manipulating large numbers of text files and even leveraging Terminal commands. There is something that’s just very friendly and universal about Python, and it’s cross-platform support makes me believe that the time I put into it today will continue to payoff for a very long time—even in a possible future where macOS and its Apple-centric scripting languages fade away.
DEVONthink
2016 was the year I finally parted with Evernote, and I couldn’t be happier with my decision to go all-in on DEVONthink Pro Office. I’ve been able to bring all of my content management under a single roof and enjoy the unrivaled organization tools, search operators, OCR, and security that DEVONthink offers. If you are a macOS/iOS person, I can’t recommend DEVONthink products enough.
As 2016 draws to a close, and I begin organizing tax season information, it’s hard to believe I used to manage tax docs offline because I didn’t trust Evernote’s cloud storage. Now everything is securely accessible on my Mac, iPhone, and iPad.
Static blogging
I left SquareSpace for Jekyll in 2016. Eight months later, I still love the concept of a static website and the flexibility it’s given to my writing workflow on both the Mac and iOS. I also learned so much in the process of converting my blogging setup to Jekyll—Python tricks, etc. It was a great move, and I love the independence of having my own site, even if it’s just a small flicker of light compared to the social/aggregator sites that many think “killed” blogging. They haven’t killed this one.
Long live the GIF!
This year, I realized that the latest version of ScreenFlow lets you make GIFs. It’s simply another export option. GIFs take almost no time to create and are so much better for showing someone how to do something when you want an animated image but don’t need audio. If a screenshot is worth a thousand words, a good GIF is worth a thousand follow-up questions that don’t have to be asked.
Miscellaneous Mac tips
Sometimes the small, barely noteworthy adjustments to workflows make the biggest cumulative difference.
The best things I read and listened to in 2016
I read a lot of things and listened to a lot of things in 2016. Mentioning it all would be time consuming and also dilute the best, so I’ll just pick one from each category:
Together, these two works are a nearly perfect representation of my non-professional interests at this stage of my life: understanding the universe outside and within my mind.
Fire in the Mind
I don’t remember how I stumbled across George Johnson’s Fire in the Mind, but it ended up being the most holistically fascinating thing I read in 2016. Johnson uses his intimate knowledge of physics and Tewa Indian culture, rooted in the hills of the Santa Fe area of New Mexico, to make fascinating connections between the two most fundamental human constructs for explaining reality: science and religion.
Fire in the Mind is truly universal in the sense that it weaves countless threads through the quantum and classical realms that define the universe that we’re capable of perceiving as humans. I’ve included a few of my favorite quotes below, interspersed with my comments and related things.
For starters, I really admire how Johnson questions everything, even imposing humility on concepts like Darwinism that in modern life seem indisputable from a scientific perspective:
Once a filter becomes installed in the brain, it bends everything we see. Gazing out on the jungle, a Darwinist sees the beauty of natural selection, an invisible Maxwellian demon sifting order from randomness in a Sisyphean effort that ultimately cannot succeed. A structuralist imagines instead a multidimensional fitness landscape, the vortices of its basins ensuring an orderly world. Like all of us, both are faced with never knowing the extent to which the patterns they see are out in the world or imposed by the prisms of our nervous systems.
We are just smart enough to realize how incapable we are of ever answering the questions we come up with:
We are endowed by nature with this marvelous drive to find order. But we constantly bump up against our limits. Just as a frog can only see objects that move across its visual field with certain motions, so are we aware of only a tiny part of the electromagnetic spectrum. But we assume that we can supplement our senses with our minds and with our mathematics. We theorize about frequencies beyond our horizon, the invisible rays of infrared and ultraviolet light, of gamma and radio waves, and we build instruments to detect them. Then we weave stories about how these hidden worlds must be. When we fail to find symmetry in the world around us, we imagine extra dimensions, higher vantage points from which the world will regain its perfection. But for all our efforts, the whole truth will always elude us. Try as we might, we will never succeed in squeezing the immensity of creation into our tiny heads.
Related: Watch Carl Sagan explain the fourth dimension by imagining creatures confined to a two-dimensional universe.
The inherent limitation of using mathematics to explain the universe is that we don’t have a system for explaining mathematics itself:
Gödel, after all, proved that mathematics itself has its limits. In his famous incompleteness theorem, he showed that no logical system can be used to prove its own consistency.
And so:
Any effort to explain the world must begin with a leap of faith.
Sidebar: For me, this brings to mind one of my favorite conclusions from the great physicist Charles H. Townes in 1966:
… if science and religion are so broadly similar, and not arbitrarily limited in their domain, they should at some time clearly converge. I believe this confluence is inevitable. For they both represent man’s efforts to understand his universe and must ultimately be dealing with the same substance.
Johnson also wonders how the existence of science and information can be explained in the fabric of the universe. What is science? Is it a platonic form, or part of the “real” world?
… numbers, equations, and physical laws are neither ethereal objects in a platonic phantom zone nor cultural inventions like chess, but simply patterns of information—compressions—generated by an observer coming into contact with the world.
… could information also be an artifact, another of our projections? After all, there are not really any 1s or 0s inside a digital computer, just voltages that we chop up by arbitrarily drawing a line and declaring everything below it 0, everything above it 1. Everything going on in the machine could conceivably be described in terms of continuous currents of electricity without recourse to this notion of information.
Maybe we’re just keeping ourselves busy:
Sometimes the intelligence of our species seems like a tiny flame flickering on the periphery of a vast blackness, trying to illuminate the void. Who gave us this burden? Will anyone or anything beyond our celestial campsite ever care? If this web is just something we are spinning for our own amusement, it will die along with its creators.
Our simultaneous advantage and curse compared to other organisms is that we can conceive of these questions at all. Imagine if you could make a conscious being out of legos, then enclose him a box with extra legos that have no obvious form. Imagining watching him wonder why, though made of the same parts as the leftovers in his tiny universe, he is animate and conscious. Imagine the stories he would invent about his possible creators—perhaps even conjecturing that through some improbable shaking of his box, he was formed.
It’s quite possible all order that sits atop the quantum world is a computer-like simulation, and the conditions and constraints of that simulation likely confine us forever to our tiny box without any ability to think outside of it, even if we dream we can.
The Science of Mindfulness
Speaking of the perils of a runaway mind, I’ve danced around the subject of mindfulness for several years now—reading mostly things written from a Buddhist perspective. In my experience, most such readings ultimately come across as marketing material, so to speak, for Buddhism.
I think if ever there was a religion or religion-like thing that I could unequivocally subscribe to, Buddhism would be it. But alas I find that Buddhism has too many social impracticalities and cultural stigmas that cause it to clash with my immediate surroundings in the southeastern United States—sort of like trying to adopt a vegan diet in the Arctic. I also think that the more dogmatic anything sounds, the less credibility it has with me. I can’t change how I’m wired.
Dr. Ronald Siegel’s audio course, The Science of Mindfulness, was a welcome change to the typically Buddhist-centric things I’ve studied in the past on the topic of mindfulness and meditation. As the name suggests, Siegel presents mindfulness from a more universal perspective without relying on any particular religious support. When he does mention Buddhist teachings, it’s more from a psychological and referential perspective. He also notes how western innovations in mindfulness are bettering practices that were traditionally only Buddhist. For me, this was a welcome change from the usual rhetoric that frames eastern traditions as panaceas for everything that’s wrong with the west.
In my mind, if I could reduce mindfulness to a single practical concept, I would describe it as a thought technology designed to combat a basic problem of the human mind. As Siegel explains:
The human mind did not evolve to be naturally happy. It evolved to survive. Happiness is not a natural state for a human being.
Persistent pessimism was a very useful thought technology for early humans. Confronted with an object on the horizon that might be a beige rock or might be a crouched lion, surviving humans were biased to act as though it was a lion. Even if they were wrong, they lived another day. People who systematically worried more survived longer than those that didn’t.
This persistent negativity bias gives rise to thought processes like “things have gone really well lately, so something horrible must be about to happen soon.” Put simply, we are poorly evolved for our modern environment, which is largely devoid of the perils our minds are equipped to avoid. Absent the need to dodge predators or search for food, all our minds can do is create illusions to worry about.
No amount of prosperity exempts a human being from these feelings. The human mind will create problems for itself no matter how good things get. In fact, the better off someone is financially, the more they have to lose quantitatively. Hence the fear-driven greed that causes Wall Street billionaires to do unethical things to protect themselves from loss.
Being able to see thoughts more as fleeting objects and understanding that your perception of yourself is entirely an illusion created by your experiences and emotions is the art of mindfulness. The implications are profound for becoming more mindful in the modern world, which is loaded with attention-stealing stimuli.
I truly believe cultivating mindfulness is the next frontier in human evolution. Innovation in thought technology will matter far more to our well being than any computer technology. If you have any interest at all in mindfulness, I can’t recommend Siegel’s course enough.
More macOS Preview PDF trouble
Brooks Duncan performed several tests to confirm that Preview on macOS Sierra 12.12.2 destroys the OCR text layer of certain PDFs.
I’ve been extremely happy with PDF Expert as my default PDF app for macOS. I promoted it to my primary PDF app soon after upgrading to Sierra because I noticed that Preview would also break the internal table of contents structure of PDFs.
I never thought I’d see the day when I couldn’t even trust something as basic as a PDF to Apple’s software. The new PDFkit stuff in Sierra should be an embarrassment to Apple. PDF support should just work.
Pandoc and Python
I’ve talked before about using Pandoc to convert Markdown to LaTeX. I’ve been using it a lot this year, and it’s been great to write more in Markdown and code less in LaTeX. Pandoc does a really nice job converting Markdown and even characters like $, %, —, etc. into the correct LaTeX syntax (\$, \%, ---, etc.). It also leaves alone any chunks of LaTeX I intersperse in my Markdown files (e.g. equations) so that they’re still there in the final LaTeX output—married with the LaTeX created from Markdown.
So that’s all the good. For me, the bad of Pandoc is that I don’t think the LaTeX code it generates is very nice to look at. It typesets just fine, but Pandoc inserts extra line breaks by default and does funny things with itemize and enumerate environments that make reading the LaTeX code later difficult—especially annoying when I need to go back into the LaTeX to edit/add things in the future.
Fortunately I’ve been able to address these shortcomings by learning more about Pandoc’s options and bringing Python into the mix.
To illustrate, let’s start with some Markdown written in Ulysses, which I use a lot for writing on both macOS and iOS:

If I copy that Markdown to my clipboard and run a basic pandoc command in terminal like:
pbpaste | pandoc -f markdown -t latex | pbcopy
It will create the following LaTeX (shown in Sublime Text 3):
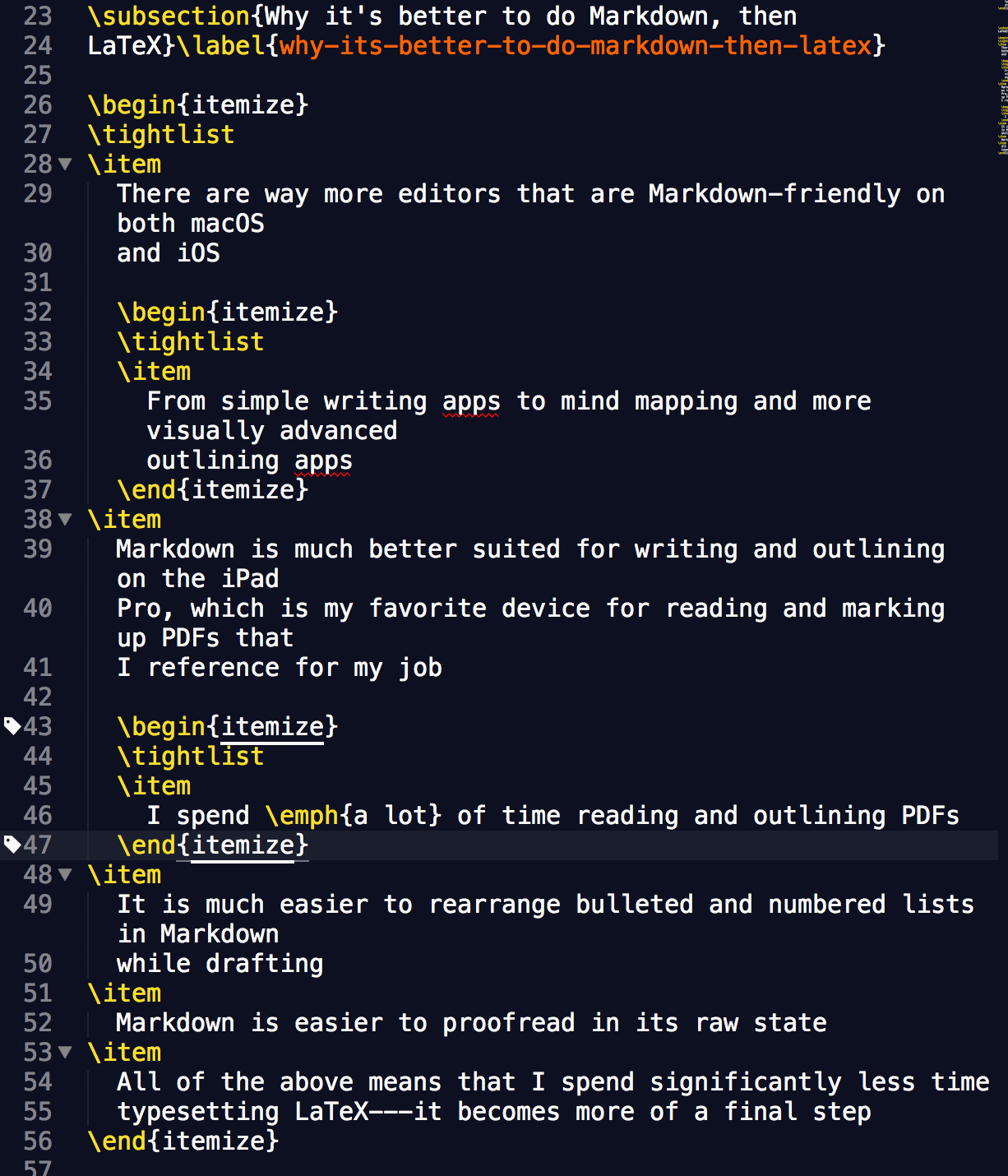
If I never need to look at the LaTeX code again, this isn’t so bad. It will typeset just fine. But it’s very messy. Namely:
Fortunately, Pandoc’s developers later added an option to preserve wrapping, which solves problem 3 above:
pbpaste | pandoc -f markdown -t latex --wrap=preserve | pbcopy
To fix problems 1 and 2 above (as well as others), I turned to Python, a move that was very wise in hindsight because it lead me to finally develop a reliable process for executing shell commands within Python—something I can see myself using a lot in the future for all kinds of things.
This is my current Python script:
import subprocess
from subprocess import Popen, PIPE, STDOUT
import sys
import re
# Function to get system clipboard contents
def getClipboardData():
p = subprocess.Popen(['pbpaste'], stdout=subprocess.PIPE)
retcode = p.wait()
data = p.stdout.read()
return data
# Function to put data on system clipboard
def setClipboardData(data):
p = subprocess.Popen(['pbcopy'], stdin=subprocess.PIPE)
p.stdin.write(data)
p.stdin.close()
retcode = p.wait()
# Get Markdown copied to clipboard
input_text = getClipboardData()
# Popen pandoc shell command
p = Popen(['pandoc', '-f', 'markdown', '-t', 'latex', '--wrap=preserve'], stdout=PIPE, stdin=PIPE, stderr=STDOUT)
# Pass Markdown text to pandoc through stdin and get raw LaTeX from pandoc
latex = p.communicate(input=input_text)[0]
# Clean LaTeX:
latex = re.sub(r'\\tightlist\n', r'', latex) # remove \tightlist
latex = re.sub(r'\\item\n\s+', r'\t\\item ', latex) # join \item with its text on a single line; also put tabs in front of \item
latex = re.sub(r'\\label.*', r'', latex) # remove all LaTeX labels
setClipboardData(latex)
getClipboardData() and setClipboardData(data) are functions that I stole from Macdrifter. They are really handy for working with the clipboard in macOS. Since I work with Markdown in a lot of different ways, copying it to my clipboard has been the best all purpose way of getting it into a script like this.
The biggest innovation in this script, for me, is Popen and communicate from the subprocess module. This is really powerful stuff because it basically lets me execute shell commands and work with stdin and stdout just like I would if I was running ad hoc Terminal commands.
In my script, communicate passes the Markdown text via stdin to the pandoc shell command, then sends the pandoc output through stdout back to Python as a string. This was a huge milestone because once I had the raw LaTeX in a text string within Python, it made it possible to use Python to clean the LaTeX any way I liked.
The final part of the script runs several regular expression substitutions to clean the output more. Honestly, these could have been done just as easily with the basic replace method, but I have a commitment to myself to use regular expressions as often as possible to get better at them.
Running the script results in LaTeX that I think is much easier to read and takes up a lot fewer lines:
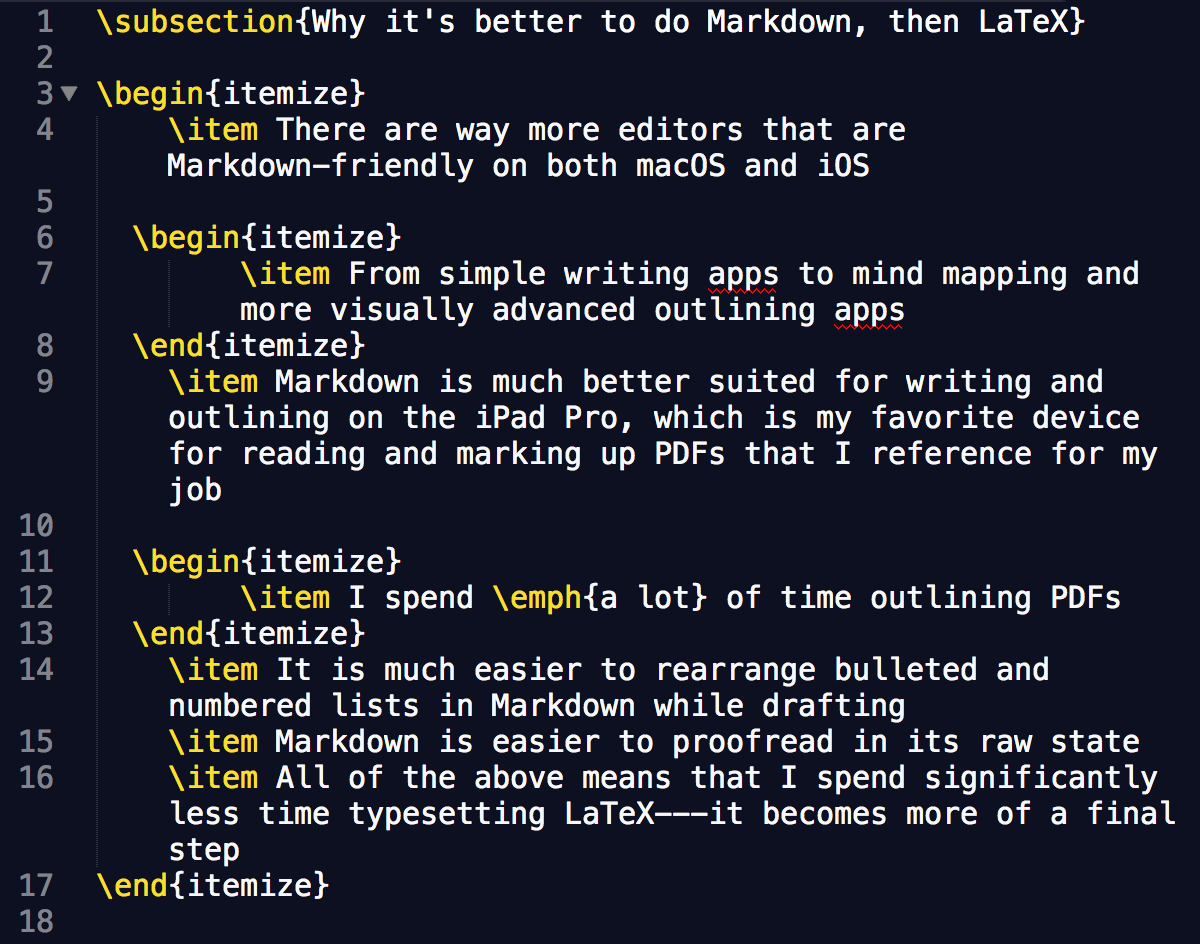
I’m sure there are a thousand better ways of accomplishing what this script does for me, but I’m really happy that I can continue writing more LaTeX-bound text in Markdown and know that the final LaTeX will be even easier to work with in the future. It’s also opened the door for a lot more Python automation, which on some level, is probably the entire point of investing time in automation.
Two great iPhone scanning apps
As great as the iPhone’s camera is for taking pictures of people, landscapes, and cappuccino milk foam, it’s also turned the iPhone into the most obvious choice for short to medium-length document scanning.
I use ScanBot almost every day to capture everything from receipts to miscellaneous paper mail items. I keep it on a black and white filter setting, and the scan quality is incredible. The resolution of text is right on par with what I get from a desktop ScanSnap scanner, and when I OCR it later, the text layer is perfect 99.9% of the time.
The other day, I even used ScanBot to scan an 80-page section of a textbook that I didn’t want to butcher for my ScanSnap. ScanBot recognizes page borders automatically and nearly instantly, making multi-page scanning a breeze. It’s amazing.
Just recently I discovered TextGrabber via David Sparks. TextGrabber does just what the name says: you simply take a picture of something containing text, then select the portion of the photo containing the part you want. TextGrabber OCRs just that cropped region, allowing you to grab the text right away.
For a lot of things, this is way more efficient than storing a photo or PDF that would have to be titled with keywords, saved, and/or OCR’ed later. Things like business card information, serial numbers, a block of text from a newspaper article, etc. TextGrabber is made by ABBYY, who makes, in my experience, the most accurate OCR software in the world. DEVONthink Pro Office ships with ABBYY’s OCR technology, and it’s by far the most thorough I’ve ever used.
Inbox self flagellation
Kristin Aardsma on letting go of Inbox Zero:
Inbox Zero is an arbitrary goal; there will always be another customer email or phone call or tweet. Inbox Zero is a fruitless fight for control. It became an image that tied us to our screens, that swallowed any self-care practices we had instilled over the years. It also became a habit of treating our customers less like humans who needed support and more like screens to get rid of.
I have a deep respect—and I would go so far as to say deep understanding—of the philosophical roots from which Merlin Mann grew Inbox Zero into a internet movement in the mid-2000s. But that was a very different epoch in internet history.
In the mid-2000s, email was the primary form of text-based internet communication, and it was actually feasible to deal with it like a paper inbox. But so many inboxes have proliferated since then, and email has only gotten worse. Today, to have an Inbox Zero mindset is to be adversarial with one’s self.
There is just too much to read. Too much to process. Most importantly, too little to be gained by zeroing out an inbox in any moment of earth’s rotation about its axis. In the last year, more than ever, I’ve realized the most enlightened decision is to let the dam break, walk away, and focus on work outside of open inboxes.